Today, both enterprise IT leaders and line of business application owners are facing similar challenges about securing workloads in public cloud such as AWS. While application owners focus on balancing agility and security of their production workloads, IT leaders, CISOs and CIOs have a broader responsibility to assess and enforce security of all the workloads in cloud – a multi-cloud security objective that includes both on-premise and cloud. CISOs and IT leaders are clearly worried as more applications and workloads move to cloud but they seem to have very little visibility into the overall state of security, compliance and risks of cloud. Pushing the “cloud security problem” back to application owners is not a realistic solution either as each application team might not have the right security focus, knowledge or competency to keep their workloads secure in cloud. CISOs also suspect that application owners might be trade-offing security against agility. These are some of the challenges facing enterprise IT in how to effectively govern multiple cloud AWS accounts and app teams. As organizations mature in adopting cloud, enterprise IT needs to start playing a critical role in defining, enforcing and automating “minimum viable” security of cloud workloads for all application teams. They need to do this of course, without impacting application team’s agility and flexibility. We believe that cloud security is a shared responsibility between both IT, CISO and application owners. We also show how a security policy automation solution can effectively be used by both enterprise and application owners together to keep cloud workloads secure at scale.
Three CISO challenges for public cloud workloads
Enterprise IT and CISO faces complex challenges in managing security, compliance and risk across hundreds of different AWS cloud accounts used by application teams or lines of business teams within their company:
- “We have hundreds of AWS accounts and application teams using cloud for production. Are all these hundreds of workloads in multiple AWS accounts really secure?” – one of the CISO’s I talked to recently expressed such concerns.
- One size of compliance does not fit all app teams – some of the AWS accounts due to their nature of workload might require different set of compliance frameworks such as PCI or HIPAA. How does IT/CISO help in enforcing different levels of compliance across multiple AWS cloud accounts?
- Finally, how does IT make sure security does not slow down application team’s agility and flexibility and yet provide sufficient guardrails on security. When you have hundreds of developers making changes to cloud every hour and day, they do not want to be slowed down by being handed down compliance and security checklists from IT.
So, how does a CISO govern security and compliance across all lines of business app teams at scale?
Is embedding security engineer in each application team or a security policy document a viable solution?
One of the approaches many enterprises have taken is to embed full time or part-time security engineers in each of the application team. While this approach can work at smaller scale such as a few application teams, this is clearly not a scalable solution as enterprises have dozens to hundreds of AWS accounts.
Some enterprises create 100 page security policy and controls document (pdf/Excel) that they expect all application teams to follow. However, a manual process such as this will clearly slow down the application teams and is not acceptable solution either.
When you want to have both scale and agility, security automation is the only clear solution for enterprise IT to manage multiple accounts. Let us look at the steps enterprise IT must take to anchoring minimum viable security across multiple application teams.
Enterprise IT – Start defining and enforcing security controls through automation
I. Define security and compliance controls inventory and SLA
One of the first steps enterprise IT must do is to define a set of security and compliance controls that are fundamental for security of all workloads in cloud. Every line of business (LOB) application team using cloud must be assessed with these set of controls for non-compliance violations.
For AWS, the best sources for controls are given in the two standards – CIS AWS Foundation and CIS Three tier web application policies. There are 100+ policies that define security controls for AWS that cover all these areas, a few exemplary examples are given below under each category:
- IAM
- Ensure IAM password policies
- Networking
- Ensure no security groups allow ingress from 0.0.0.0/0 to port 22/3389
- Logging
- Ensure CloudTrail is enabled in all regions
- Monitoring
- Ensure a log metric filter and alarm exist for usage of “root” account
- Application
- Ensure Databases running on RDS have encryption at rest enabled
For certain workloads requiring a higher level of compliance such as FedRAMP or NIST 800-sp3 or HIPAA or PCI, additional policies with controls must also be created. These set of controls forms the “controls inventory” that an IT organization should define and maintain within the company.
Finally, IT must also define SLA for resolving the critical and high priority violations, such as fix critical violations or security findings within 1 week.
II. Enforce controls on all public cloud accounts through continuous monitoring
Policy automation solutions (such as BMC SecOps Policy Service) allow IT to automatically and continuously (eg. daily or hourly) run compliance checks across hundreds of public cloud accounts as shown in the diagram below.
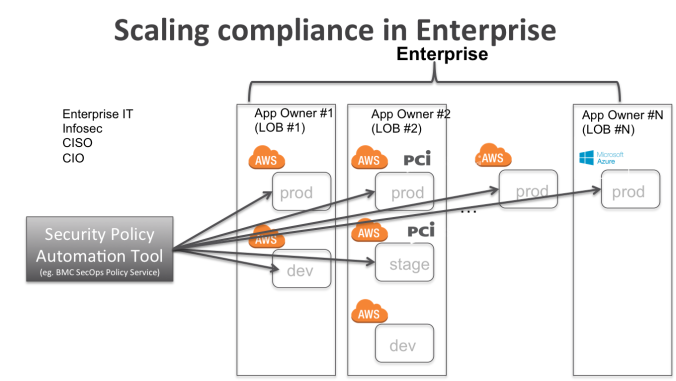
In this architecture, a security policy automation tool assesses security posture of all the 1..N AWS accounts in an enterprise. It provides security and compliance visibility at aggregate level for CISO as well as for LOB application owner. Security policy automation tools also must support multi-cloud control compliance to extend support for AWS, Azure and Google clouds.
Finally, if certain AWS accounts require NIST, HIPAA or PCI level of compliance, the security policy automation tool must allow different policies enforced on such accounts. This enables a unique set of compliance policies applied to each application team cloud accounts based on the compliance needs of the workloads. For example, if application #2 needs to be PCI compliant, then a PCI policy with its controls should be assessed against cloud accounts owned by application team #2.
III. Collaborate with Application Owners for remediation
Enterprise IT should continually monitor security and compliance of all AWS (and Azure, multi-cloud) accounts for the set of controls that they have defined as a minimum security for all AWS accounts. It should then develop a collaborative approach to alert the LOB application teams about critical violations of control policies and work with application teams to ensure that the violations get resolved within the SLAs.
So, who is responsible for cloud security – Enterprise IT or Application Owners?
Enterprise IT must start to assert itself in cloud security by extending the security it knows well in on-premises to cloud. Of course, traditional security practices from on-prem cannot be simply used “as-is” in cloud. Instead, a very prescriptive automatable new set of security policies for cloud technology are the first key steps for enterprise IT to establish a baseline for cloud security in the organization. Investing in a policy automation such as BMC SecOps Policy Service or a CASB solution would be the next step for enterprise IT to start getting visibility into security posture for all cloud workloads spread across multiple cloud accounts. Finally, IT should work closely with each LOB application owners for remediation.
LOB application owners also have an equal responsibility of security of their workload and must work closely with enterprise IT to ensure that security findings are acknowledged, addressed and remediated within SLA.
We believe a shared responsibility model between LOB application teams and enterprise IT/CISO would be the best approach to secure cloud workloads.
BMC Policy Service is a security automation tool that you can get started in less than 30 minutes and secure all your buckets and cloud resources – https://www.bmc.com/it-solutions/secops-policy-service.html.